batch normalization
ICML2015 google的一篇文章:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
在机器学习领域有一个重要的假设:独立同分布假设,训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。而本文提出的方法就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布.
方法提出的目的是加速ANN训练的收敛速度.附带了诸多意想不到的效果.具体我们从头道来:
为何NN中送入网络前数据需要归一化?
如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
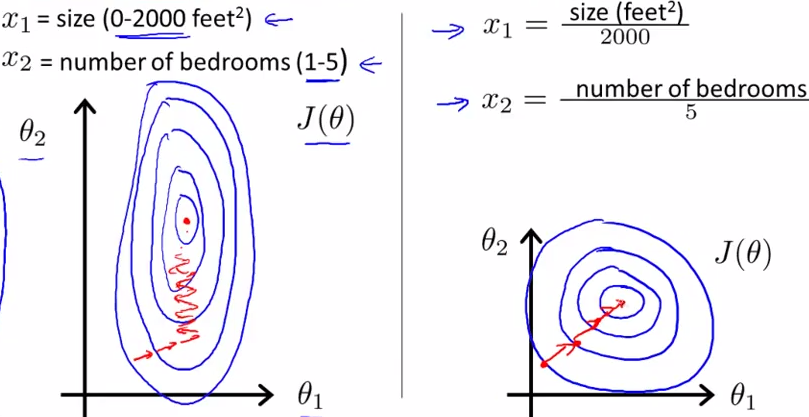
大概就是这么个意思,NN才不管你哪些特征应该有多少的权重,一切都是数据驱动的,但在一开始是一视同仁的,特征之间的取值范围如果一开始差别巨大,且恰巧朝着其该有权重的反方向差别.那么网络的收敛可能就需要更久一些,其实并不算个大问题.但是在网络层数深起来以后,这个问题还是越发显著.
那么同理,对于input有这样的归一化需求的话,是不是每一层的输入都应该有这样的需求?
当然,一层网络你也会做归一化,同上一致的问题,如果事先能保证特征之间取值范围一样,甚至更接近分布的权重(应该不可能),那么就不用做归一化.
这里我们着重看一下题目中的Internal Covariate Shift.首先,Covariate Shift表达的意思是什么呢?
一句话说就是当你的训练集的样本分布和测试集的样本分布不一致的时候,你训练得到的模型是无法有很好的泛化能力.这个偏差就叫Covariate Shift.而 Internal Covariate Shift这里的定义是,深度网络中随着训练进行,参数不断变化,而导致的每一层输入的分布变化(如果把该层输入看作训练集分布)引发的shift叫做Internal Covariate Shift.
本文借鉴之前whitening操作的思想,简化了白化操作的步骤以及使用batch的期望特性来表征整体特性.
这些观点都是文章的,我本人读完也并没有理解这里面它说的这个道理,我觉得就是为了让自己的文章具有更强的理论性.而这种把送入激活函数前的值进行normalize的做法,其实以下的理解更加直观与能够接受:
我们回到经典的梯度消失问题,我们都知道之前提到过,sigmoid等函数会存在饱和区域.也是这样的问题使得relu成为主流.但我一直认为relu在表达能力上弱于sigmoid,当然深度网络中激活函数的表达能力与整体表达能力的关系是怎样的谁都说不清楚. 好了不提这些,本文这种在输入激活函数前做normalization的方法结果体现的很直接.每次把送入激活函数前的输入限制在sigmoid的梯度大的区域(0均值),使得梯度消失问题得到解决~
可是,事情真的有这么简单嘛?如果只做归一化,这个连我也有想过.然而只做归一化会将非线性表达能力大大下降...那么文章提出了以下解决方法,也是我等学渣炸死也不会想到的,甚至看到也似懂非懂的:
为了保证非线性的能力,对normalization后的结果又进行了变换重构(scale和shift),并且这两个参数均可以学习得到:

我们可以看到当gamma等于batch输入x的标准差时,beta等于minibatch的均值时,yi就等于了xi 也就是说这个normalization还囊括了不做normalization的情况...看上去是不难理解,但自己想可还真是不知道为啥会想到这个.
那么这个可学习的参数使得标准正太分布变为广义正太分布,但是却是数据驱动的.所以会自动地寻找最适合的使得梯度更新合适的那一款normalize,这样就是把如何在更新速度(反映在accuracy)与非线性表达(反映在accuracy)中谋求一个平衡的任务交给了数据而不是人来完成.
由于采用了BN,输出变成了z=g(BN(Wu+b))这样子,为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。因此最后BN层+激活函数层就变成了:
z=g(BN(Wu))
从另一个角度来理解,BN可以说是对上一层的输出做了一个聚拢操作.通过线性变换使得上一层的输出尽量靠近batch均值.减少了batch内部variance从而使得倘若由batch 作为dataset造成的 dataset bias得到改善.
BN还有啥好处?
1.移除或使用较低的dropout。 dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。 2.降低L2权重系数。 还是一样的问题,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。 3.由于上面的介绍,显然学习率的设置变得不重要,不需要care学习率如何调参
值得一提的是,在CNN中每一个特征map只有一对BN的参数需要训练,与maps的大小无关.