resnet
Highway network,一种data-independent的加速深层网络梯度下降的思想,是后面深度残差网络的基础idea
http://blog.csdn.net/l494926429/article/details/51737883
why深度残差?
深度的理由不解释了,resnet工作发现简单地堆叠网络深度,甚至可能造成深层比浅层更糟糕的结果.且更深的网络不容易训练,resnet的主要贡献是解决了梯度消失的问题,从而使得训练更深的网络更加容易.
how如何达成的?
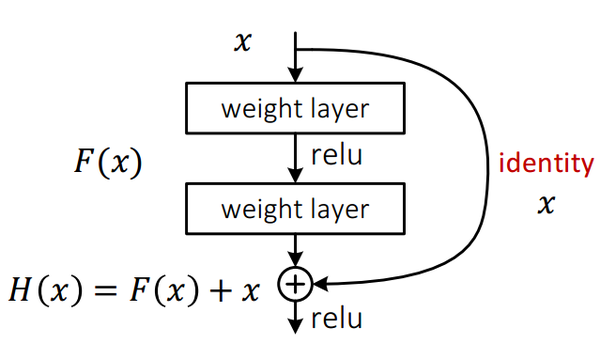
如上这个简单的结构被称作残差单元,很显然,这个单元的输入x,输出为H(x)=F(x)+ K(x)
这里K()是identity映射,也就是说K(x)=x
同样,下面H(x)过的relu称作G(x)的话,作者也建议把这里的relu换成identity映射.是不是不知道我在讲什么...因为还没有到重点.假设整个网络由这样的残差单元垂直堆叠而成,那么最终输出层:
H(Xl)=F(Xl)+Xl-1 ,而Xl-1恰恰是F(Xl-1)+X(l-2) ,
如此递推下去......
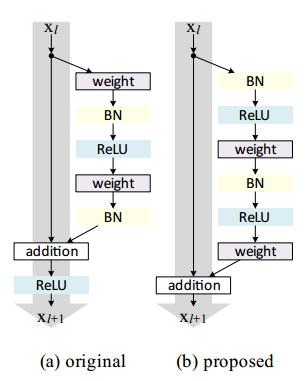
于是就是把激活的位置调整了一下,放在了x输入到下一层的残差支路中.另外一种解释在Kaiming的identity
mappings一文中有提到:在残差支路尽头的relu激活函数将输出值的相当多一部分truncate(截断)成0,所以导致了
在主干道的传输数据总是在递增,这对网络的稳定不是一件好事。
另外需要注意的是,这种addition显然需要x和F(x)保持同样的维度因为相加是逐元素对应相加,如果不是的话addtion操作中的x需要一个矩阵映射到与F(x)等维度..y = F(x, {Wi})+Wsx.
http://blog.csdn.net/u012816943/article/details/51702520
when什么时候使用?
按照文章的说法,在训练非常深的网络的时候一定要使用残差,不然会遇到经典的梯度消失问题.可是google随后在inveptionv4指出了也不一定使用,但是如果使用inception+resnet得到的inception_resnetV2,效果如inceptionV4收敛却快.所以说目前看来,在很深的网络训练中,残差网络还是无条件地好用.(宽残差网络和随机深度还没看,看完回来补)
因为残差网络本质就是在几乎没有改变网络架构的同时,破坏了反响传播误差时的链式法则的缺陷.所以要说其缺点,大概只有:
1.中间层物理意义不强.
2.对两处identity映射的强假设(造成的结果其实并不会多大)