简单的说,就是你求解后所得出的那个函数。在求解前函数是未知的,按照你的思路将已知条件利用起来,去求解未知量的函数关系式,即为目标函数。
一般地,对于单任务,特别是使用单个神经网络解决特定问题的范畴内。我们的目标函数也可以称作结构风险函数。
而结构风险函数通常包含:经验风险函数+正则项
而经验风险函数也就是一般说的网络的输出与标准答案之间的差异的累加值,也称之为网络的损失函数。
正则项一般是根据某种特定的喜好,对模型结构的惩罚项。
最常用的指导原则是:奥卡姆剃刀原理,其“如无必要,勿增实体。”的基础理念可以解释稀疏解有些这样一些机器学习经验结论。
所以我们通常会对模型的复杂度进行惩罚,
比较常见的正则项有L1和L2 regulizer,L1惩罚将模型有效权重的个数和乘法因子lambda相乘作为目标函数的一部分。这样,当经验风险项相同时,我们会喜好模型有效参数更小的那个模型。
同理L2是依据权重的L2尺度进行惩罚,虽然相比L1没有那么直观地达到目的,但是L2由于其可导的特性更容易进行目标函数的优化
而在深度学习中,网络经常配合softmax+cross entropy做监督学习。前面详细介绍过softmax,这里说一下交叉熵损失
首先熵在物理学中用来被描述对象的混乱程度,万物自然向着熵增加的方向运动(混乱程度增大)
那么我们在数据科学中常用的概念和物理学类似,只不过我们叫做信息熵,那么对应描述的就是数据混乱的程度。
如果用贝叶斯估计去预测事情时,很显然由于已经有的数据,信息熵可以反映数据的混乱程度,同样可以反映对一件事情的期望,也就是随机变量不确定性的测量。
然后是相对熵的概念,这个我们在哈夫曼编码中深刻体会过,相对熵用来测量两个分布之间的距离,如果分布越接近则相对熵越小。
交叉熵在机器学习的大部分情况下与相对熵等价,因为交叉熵=相对熵+真实样本分布
而在监督学习的问题,我们往往假设真实样本分部就是数据库训练样本所代表的
交叉熵定义如下:

p:真实样本分布,服从参数为p的0-1分布,q:待估计的模型,服从参数为q的0-1分布
所以,比如在一个分类问题中,我们的NN往往输出一个预测分布,交叉熵损失评价了预测的分布与样本真实分布之间的距离。
特别地,由于softmax中soft的作用,刚好NN输出的结果符合一个n类的预测分布,且one hot encoding符合一个真实样本的分布
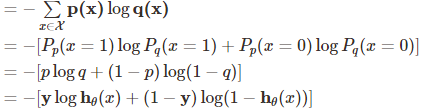
上面的式子经过推导,
我们可以得到的最终结果竟然和最大似然估计一致。故softmax+crossentropy的组合在NN中广泛使用