Introduction to Deep Learning and Self-Driving Cars
本篇大致简单介绍了自动驾驶中的一些问题,以及与人工智能与机器学习的关系。
首先,自动驾驶通过设备获取信息,然后通过软体计算并反馈操作给实体汽车,然后将这种基于软体的判断反馈于环境,这无疑是一个人工智能范畴的问题。
鉴于自动驾驶的独特性,获取的信息比较复杂,主要分为以下几个问题:
1.Localization and Mapping:回答我在哪里这一问题。
这一问题主要由地图系统来实现,比如GPS
2.Scene Understanding:回答别人在哪里这个问题
分为两个层次,radar,lidar可以告诉我们周围有什么东西,在什么位置
但是至于这些东西是什么,具体的texture information,我们则需要用camera来获取
3.Movement Planning:回答如果我想从A到B点,我需要怎么过去
通过GPS和IMU获取信息
4.Driver State:驾驶者的意图。
直接通过语音或者按键来表达,或者历史记录来获取。
讲者首先介绍了一些NN的基础知识,这里我们不再废话,然后着重介绍了
karpathy在2016的一篇有关于RL的paper,是教会电脑玩反弹球游戏。整个网络的输入时原始像素级输入,输出是一个up操作的概率。
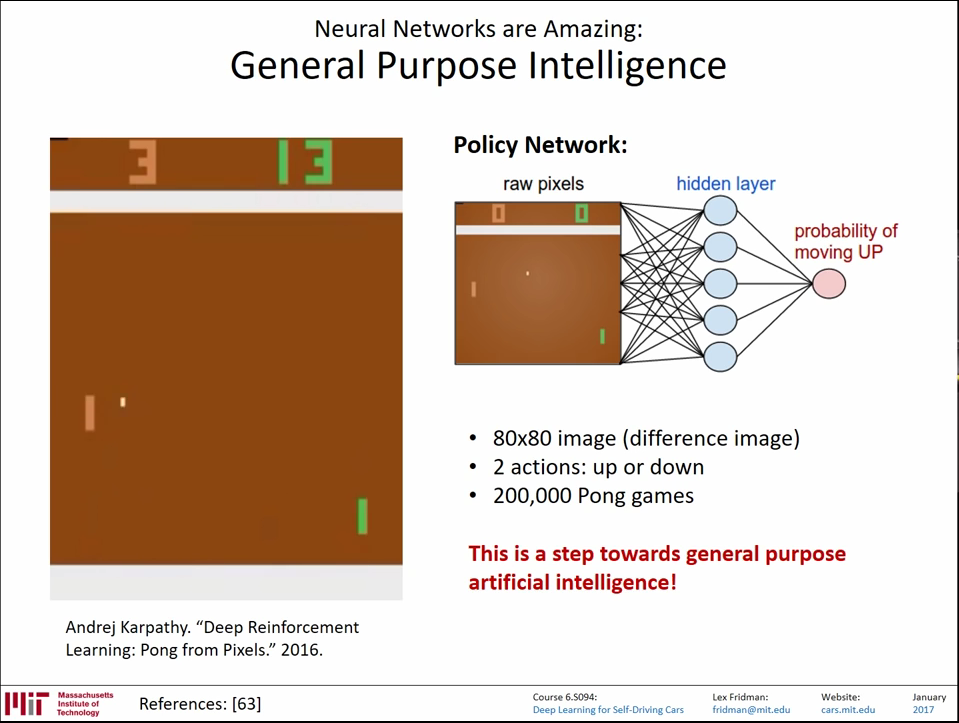 通过每个时刻的raw input,我们会得到一系列的UP 概率,将UP概率应用成操作--比如直接最大似然。那么我们就会得到一系列的 操作,从这一串的操作的结果-----得分与否,来惩罚或者奖励这些操作。
通过每个时刻的raw input,我们会得到一系列的UP 概率,将UP概率应用成操作--比如直接最大似然。那么我们就会得到一系列的 操作,从这一串的操作的结果-----得分与否,来惩罚或者奖励这些操作。
这里讲者提到,对于这种bouncing ball一类明确的结果,我们的reward很容易判断,但是对于一些不那么容易评价的结果,问题就很严重。比如,一个赛艇的游戏,如果使用游戏内score得分来作为奖惩训练游戏,就会容易陷入局部最优解:
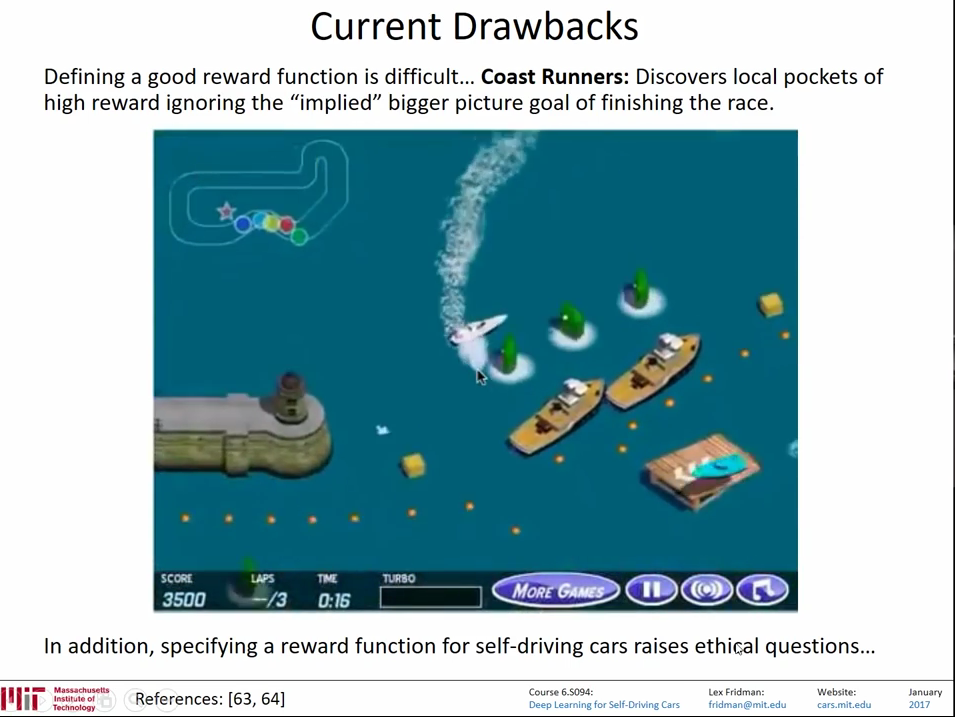
因为吃那个绿色的东西会增加得分,那个绿色的吃掉后一秒会刷新,所以AI会原地打转不断吃那个绿色的东西来得分,而不是去完成比赛顺便吃路上的绿色东西。而且也忽略了赛道上其他一些具有加分项的东西。这个就是一个陷入局部最优解的例子。
于是有童鞋问讲者,那么自动驾驶的局部最小值对应的可能是什么呢?
回答还是比较骇人听闻的:如果当一个crash无可避免的时候,
训练时的cost function是会选择保护驾驶者的安全还是路人的安全很可能在训练时陷入局部最小值。但是当这样的crash发生以前,我们都不会知道其是因为什么原因,什么情景下陷入怎样的局部最小值造成怎样的结果。只能看到结果以后,分析造成结果的陷入局部最优解发生在哪里。
可能这也是圈内很多大佬担忧自动驾驶的原因之一吧,毕竟在dl可视性与可释性皆有局限的今日,把其用在人身安全和财产(金融)上,如何去保证其结果,就连业内科学家也无法回答。
后面主要介绍了一些DL的应用,这里就不赘述了。
本章是以介绍性内容为主,没有系统地讲解RL以及DQN,更没有系统介绍自动驾驶。