Deep Q-network
所有方法都是为了解决实际的问题,我们依旧从实际问题着手,并不是为了NN而引入NN。
我们接着考虑上面的例子,上面的例子其实十分简单,action仅仅有两个选择,因为只有相邻节点是连通的,且无法原地踏步,而sate只有5个。
如果我们把计算机当成是机器人,他在玩红白机,来进行这个游戏,看到的就是raw images,图里有一个小人在被他控制移动。获取的是和我们一样的视觉信息,它不会分析问题,没有门,节点,建模的概念。他又要如何解决这个问题呢?
这里我们人如果解决这个问题,套用前面的经典Q-learning思路是,将raw image input在脑中进行抽象与推理,简化成了我们前面讲到的model,然后用Q矩阵表达动作的估值(无论之前采用任何策略,这次选择动作a能够获得的最大累计回报)。前面一个章节的例子就是在使用我们人类的知识与推理把raw image简化成状态转移模型的。
而如果电脑来做这个过程,自然raw image->模型 就是关键。
首先看看为什么不直接把像素级别也就是原始图片直接作为模型,因为每个像素值都有256个选择,一个32X32的图片,也会有天文数字级别的状态。所以如果直接把像素当做state,像前一个章节讲的矩阵存储是不现实的。
那么很显然我们需要降维,往往我们在raw iamge->模型,模型->动作估值Q 看做是一体化的,且认为Q是存在某种规律(可用函数表示)的话,我们就可以直接进行降维
从而把这个映射表达为Q(image,a) 来评价看到的状况下,进行a动作的价值
也就是无所谓image背后的state是多么大天文数字,如果它遵循某种规律比如:
$$Q(s,a)=w_1a+w_2s+b$$
就可以简单地由两个权值来解决action的估值问题,而神经网络,作为一个当下这么火的特征表达解决方案,当然不会被错过RL的领域,看起来Q函数就完全可以用一个神经网络模拟。那么DQN就来了:
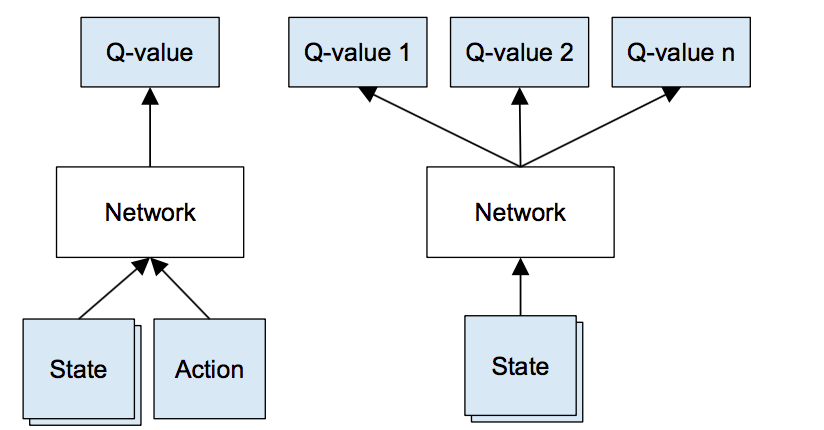
左图是很直观的把Q函数的估计交给神经网路建模,右侧是Deepmind使用的网络结构,显然右边训练起来更加高效。
我们以2013年,DeepMind在NIPS上的文章为例,这篇文章使用DQN来玩耍Atari上面的游戏。
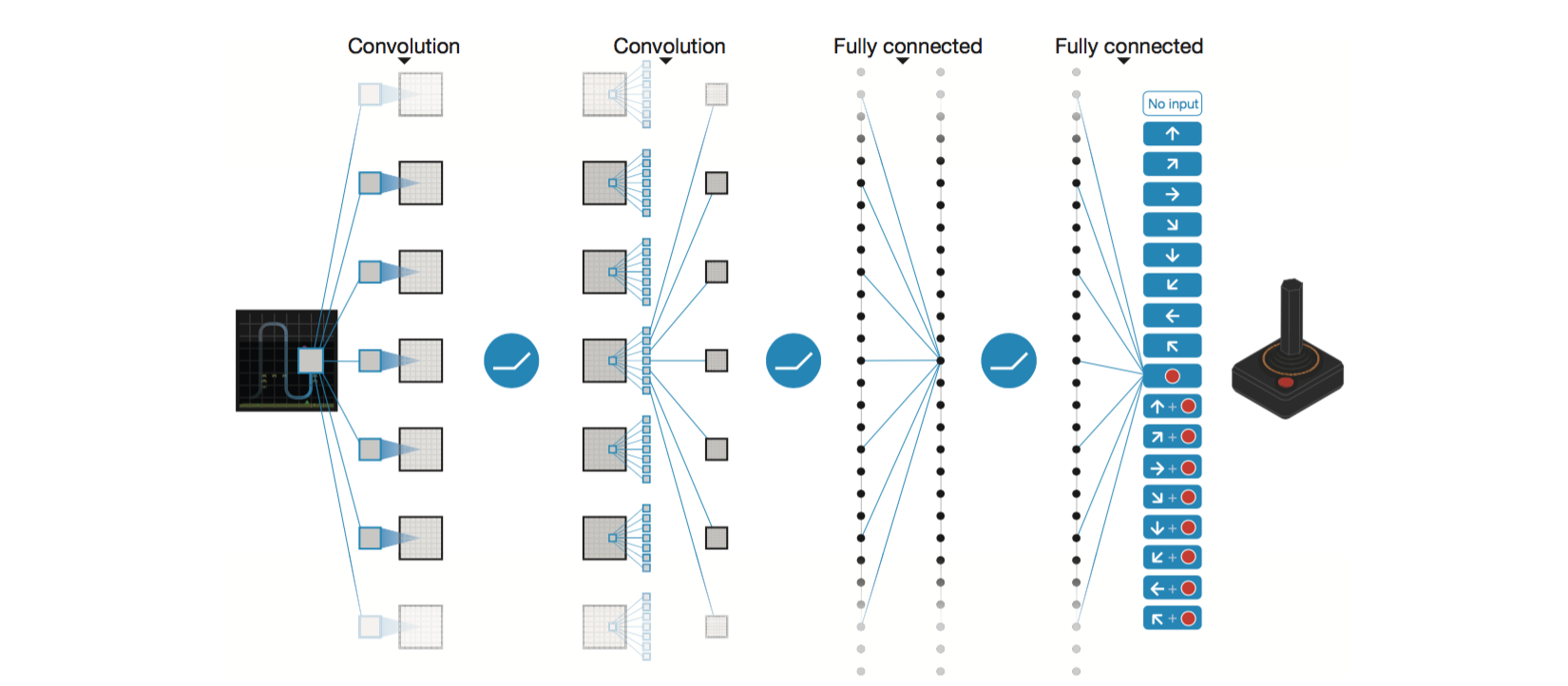 [Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013).]
[Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013).]
我们可以看到,简单的CNN网络,电视游戏raw image的输入,最后softmax输出对于各个动作的Q值估计,似乎道理十分容易。
在这篇文章中,模型依旧是我们介绍的,model-free,off-policy的,学习时用来估计价值时是遵循Q-learning的估值公式的,也就是贪婪的;做决策时考虑exploration,使用的是epsilon-greedy策略。
现在我们只需要关心一下,如何计算loss来更新神经网络的权值就好了~我们来看loss
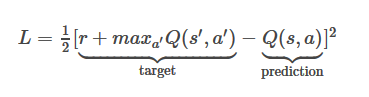
这个target如此设定正是我们前面基本Q-learning的TD(0)形式,只不过这个target也就是所谓的标签,r部分由数据观测得到(一般是游戏内部提供的score),而maxQ(s',a')部分则是通过另一次forward pass(保持权重但是改变input raw image,这其实是Nips2013 DQN的做法)得到。很显然,一张图片送入是无法进行更新的。
target部分由网络权重所决定,这与监督学习的label给定是有显著区别的。也就是计算一次loss我们需要一组(S,A,R,S')
通常S由raw image来表示,A则是通过策略比如epsilon-greedy来得到,当然greedy的Q值需要网络的forward,R是通过A做出后传递给游戏由游戏返回值,S'也是A做出后游戏进展后的画面。
但是这里有一个问题,就像我们训练简单的分类任务一样,我们需要shuffle数据,时的数据足够均匀。那么对于这些时序上有很强关系的电视游戏,我们就不能直接把即时得到的画面马上送进去训练网络。这可以想象成我们在玩游戏时不断得到(S,A,R,S')时,是在不断地无限生成我们的训练集,但是用来训练前,我们想要对数据集进行乱序处理。
这里我们需要一个称之为Experience Replay策略:
大致的意思就是说,我们先经历再回想,在回想中学习。具体实现起来就是我们先让他在这个权重下玩儿上比如5000个action。这些数据我都存下来,然后随机从中采样minibatch个(S,A,R,S')用来训练我的网络。
那么整个算法流程如下: 但是还有许多的小细节需要注意,比如我们往往不止用一张图片来表达state,可以使用连续的多张图。
但是还有许多的小细节需要注意,比如我们往往不止用一张图片来表达state,可以使用连续的多张图。
replay memory D装满开始训练前,我们都使用随机初始的权重让系统进行observe。
还有对于FPS不同的问题,我们的操作频率也应该随之改变。
可能你很难接受由一个随机初始的权重瞎胡玩儿,然后用这样乱玩儿的MAX Q估值来和自己做差然后让它收敛,为什么会得到一个好的结果,这确实很难想象,这也就是DQN奇妙之处。