GANs
对于GANs的原论文(NIPS2014),实在是过于晦涩难懂,公式部分我还没有仔细扣。然而DCGAN(Deep convolutional GAN,ICLR2016)这篇,就浅显易懂得多,毕竟只是GANs这种理论性文章在CNN上的实践。我们想通过DCGAN的实现过程来帮助搭建建立对GANs的第一印象。大家如果进一步感兴趣可以去读Ian的GANs原文~
首先GANs的主要idea:提出了一种全新的评估生成式模型的方法---鉴别判别式模型!这点还是striking的,因为生成式模型无监督,一般都是不好评价的,GANs提供一种依赖数据集的评价手段,而且还保留了无监督特性(后面解释)。
不过目前就我所知其应用还是相对局限的,只能评价其生成模型输出样本的真实性(依赖数据集)。
GANs由两个部分组成,Generator和Discriminator。Generator产生目的样本,将G的输出样本都标记为虚拟(0),和数据集的真实样本(1)一起送入一个判别式模型Discriminator,判别式模型输出结果是对逐个样本做0-1的输出,寓意是其样本真实度评价。D所期望的结果是由G输出的结果真实性打分低,数据集真实性打分高。而G的期望是D所输出的自己生成样本的真实性打分高。
Discriminator我们都很熟悉,我们仔细介绍一下这里的Generator(DCGAN的generator)
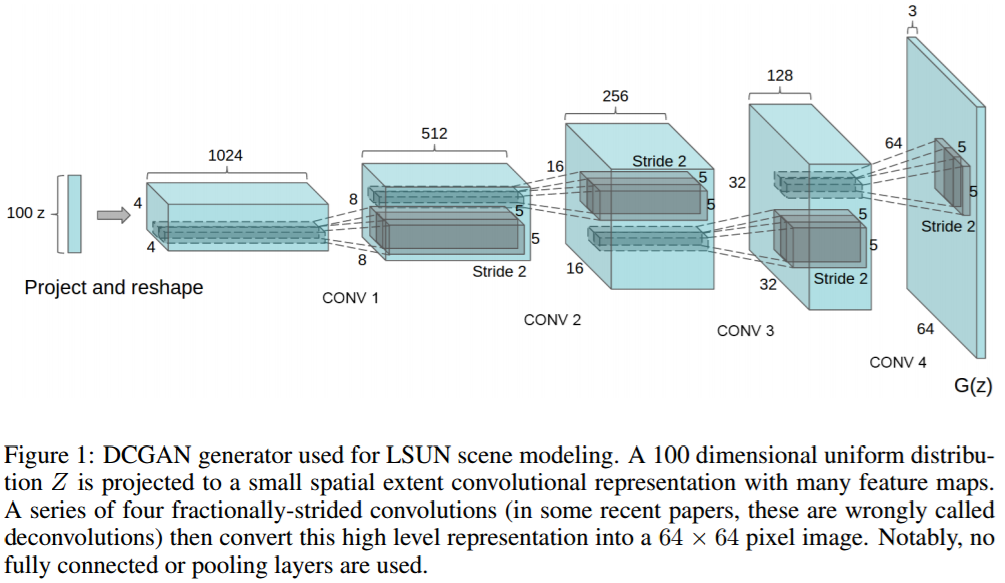 如上图所示,我们是不是看起来很熟悉呢,没错,从右往左看就是一个很普通的CNN。但是这么看只是方便我们理解,我们还是按照从左往右的Generator的顺序来仔细介绍一下这张图。Generator的输入是100维的均匀分布的噪声,我们的目的就是通过G将噪声映射到一个64X64X3的彩色图像。
如上图所示,我们是不是看起来很熟悉呢,没错,从右往左看就是一个很普通的CNN。但是这么看只是方便我们理解,我们还是按照从左往右的Generator的顺序来仔细介绍一下这张图。Generator的输入是100维的均匀分布的噪声,我们的目的就是通过G将噪声映射到一个64X64X3的彩色图像。
那么图里面的conv就是反卷积了,只不过这篇文章称之为fractionally-strided convolutions。具体一个比较简单的实现和卷积的对比如下两个动图:
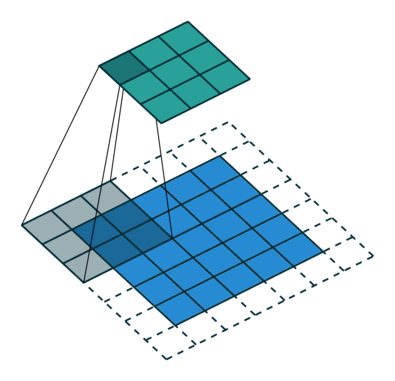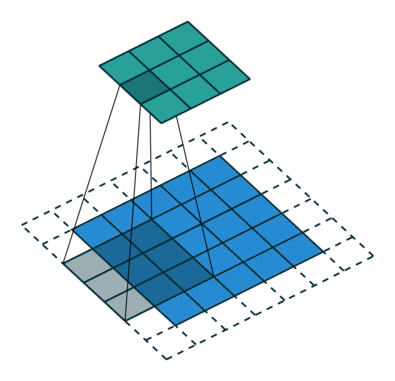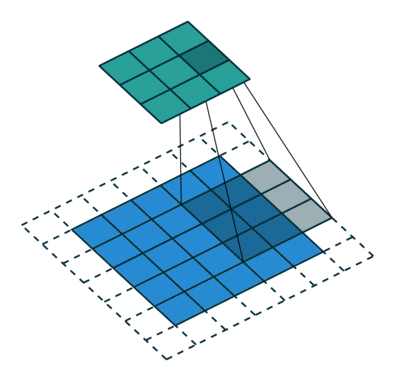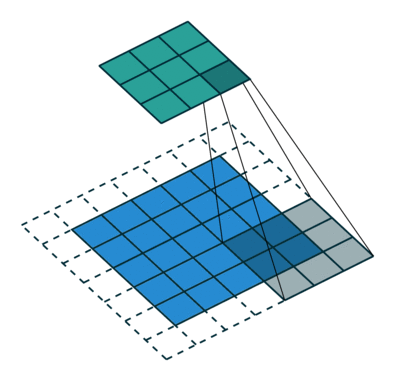
这个从蓝色到绿色的过程就是正常的PADDING=VALID类型的卷积。那么如果我们想从绿色得到蓝色部分呢?
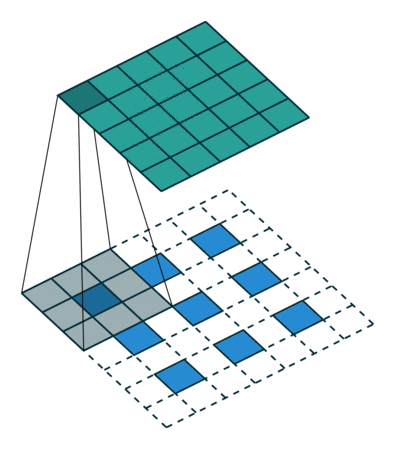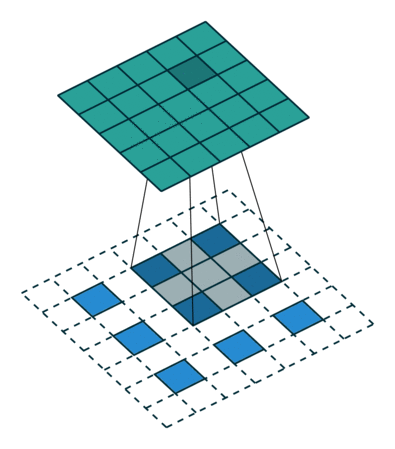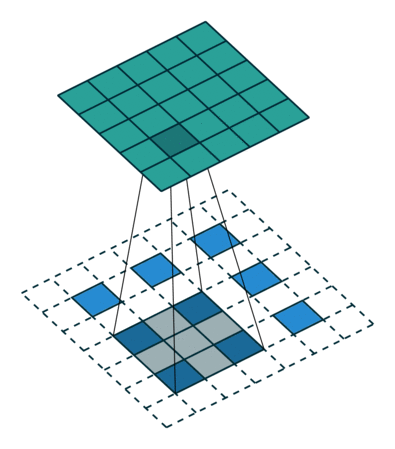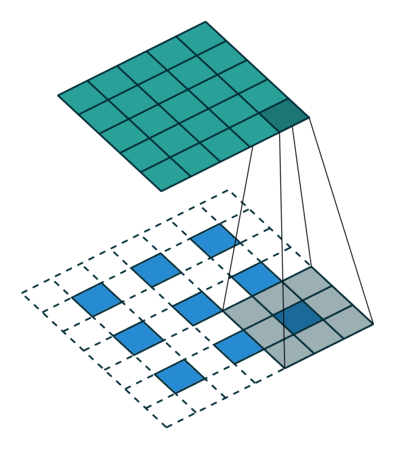
(图片都来自https://github.com/vdumoulin/conv_arithmetic)
这里的蓝色就是上面的绿色,一个3X3的feature,那么我们实现deconvolution的方法就是先zero padding,然后实施普通的卷积。那么我们的输出就是一张变大的feature,很显然,其实就是一种插值方式。
关于deconvolution并非是convolution的严格数学逆过程,所以叫它做fractionally-strided convolutions也是很有道理,步长小于一的卷积(微步幅卷积),得到的结果自然就比原图像还要大了。
G网络我们最终得到了一个彩色图像的输出,我们将其打上真实性为0的ground truth(注意,虽说是打标签,却是无监督)。同理,我们D网络的输入数据集的标签也是无监督打上的,(注意GANs并不分类,如果要多类分别生成,需要监督)
所以说,基础的GANs是完全无监督的。
D网络我们就不介绍了,待补充...